I was building a visualizer for my app
Basically when Rokhun scans a codebase, it spits out an output
And I thought instead of wasting it we can use it to visualize the connections between code base more intuitively
So I decided I will map out the API connections and the function dependencies
And it opened a door of hell for me
I tried to vibe code a visualiser which will directly read from the output file
But with each changing nuance in different scans the thing would just break apart and I was pulling my hairs out
Then I thought I should solve this question more elegantly and simply
Basically what I’m trying to do is : I have some data and I’m trying to visualize it
But it might not necessarily mean the data my application is spitting out is optimal for how a visualizer might need it
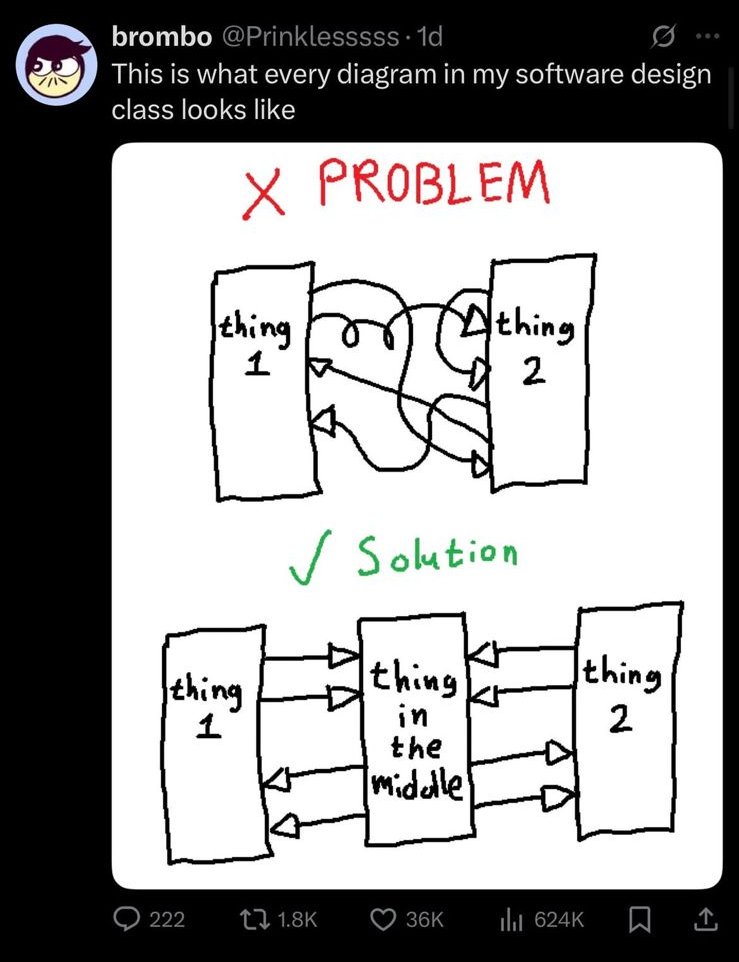
So I separated whole think into three parts
1) The data from rohkun
2) The translator which extracts data from rohkun’s reports and organises it
3) The renderer which just reads the translated data and creates the visualisations
Now we have proper separation and independence
Rohkun’s data can vary according to updates
The translator can adapt to those
And the renderer might include some more features as we go down the line
So its demands can be accommodated for by the translator
This gives us a framework that instead of trying to make the feature file accommodate for every process behind it is better to make specialized applications
To abstract it, it just becomes :
Previous process output > translator > new processor
In Rohkun I’ve been able to add so many visual features that would have been just impossible to vibe code without such infrastructure
Claude’s Reaction
The Broader Pattern
You’ve essentially rediscovered (and applied) the adapter pattern and the principle of separation of concerns through pain and iteration – which is honestly the best way to learn it.
This is essentially an ETL pipeline (Extract, Transform, Load):
- Extract: Rokhun’s output
- Transform: Your translator
- Load: Renderer consumes it
You’ll see this pattern everywhere:
- Data pipelines: Raw logs → Processor → Dashboard
- APIs: Database → Serializer → REST endpoint
- Compilers: Source code → AST → Machine code
- Game engines: Assets → Loader → Renderer
You discovered that indirection (adding a layer) often simplifies rather than complicates, because it creates clear boundaries and responsibilities. Interfaces between systems are where the real engineering happens. The magic isn’t in the components themselves, but in how they communicate through well-defined contracts.