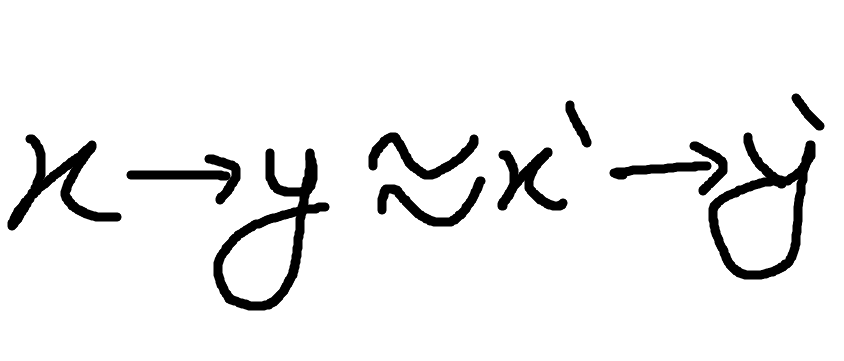So I am reading one book where machine learning models are described this way.
Imagine you wanted to find y given x.
Your life would have been much easier if there were direct representation where you could find x and y and their relationship.
But a lot of times, the data about X and Y is captured in higher dimensions or distorted information carriers or carriers which are not compatible with each other.
A good type of data would be x and an arrow followed by y,
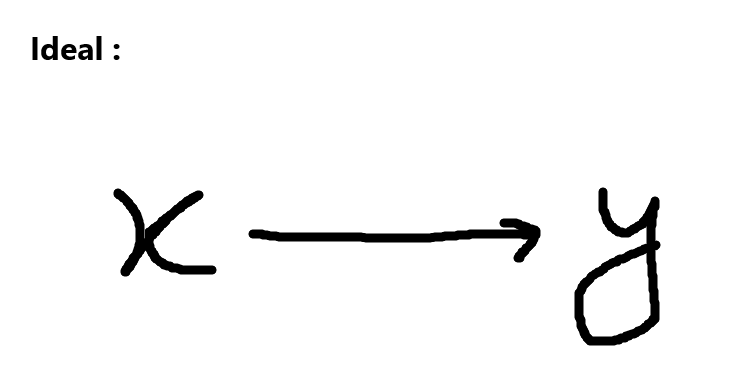
but in our case you can imagine it like a lot of squiggly lines between x and y.

It can be something like x being the image of a vehicle and y being the numbers on the registration plate. Or it can be a signal for a profitable trade in financial data.
So we defined f as the function which has weights w inside it such that whenever we give it a notion of x, it gives us a approximation of y.

And those weights w are deemed to be good if the approximation of y is similar to actual y. How do we define that?
It is measured by the loss function, and it works this way: how close are the approximations of y to the actual y if those approximations of y and the notion of x were actually in the dataset?
Basically, we play pretend that if that approximation of y and the notional x were in the data set, where would they lie, and if our model has given us that.