I am a cat. I love …
The LLM’s job is to take the sentence above and find what word comes after “love” and then find what word comes after that and that until we reach a point we are satisfied with.
But how would an LLM predict what is the next best word to use?
“I am a cat. I love…” is turned into smaller chunks called tokens and those tokens are converted into vectors, vectors that contain thousands of parameters, essentially a series of thousands of numbers. Vectors essentially define a word across thousands of dimensions. It is word defined using a series of thousands of numbers.
Matrices are things that operate on a vector and turn it into something other than the original vector. In LLM there is a part called the transformer and that transformer contains millions of such matrices.
So you have an input which is converted into tokens. Those tokens are converted into vectors and those vectors are fed into the transformer where thousands of matrix operations are taking place.
The example input has six words and those six words, let’s say, are converted into six tokens. All of those six tokens are being processed in the transformer simultaneously and they seek to imprint other vector’s flavor on to themselves. For example the vector of the word love would greatly benefit if it borrowed some flavor from the word cat because now it would be easier to predict what comes next if we focus on things that cats love.
There are different layers inside the transformer that make this process happen, where the model’s own weight and the vectors present in the operation turn the original vectors into something new. Once the process is over you will see that we have received six new vectors for the original six we sent. The vector for the word “love” was last and it is now what is called a context vector. That vector is now compared against all the words that are available within the model to find which word is most similar to it.
And whichever word is the most similar, that is the word that is most probably going to go at the end of the sentence.
Basically:
- Input sentence
- Sentence turns into many Tokens
- Tokens turns into Vectors
- Vectors put into transformer
- Each word selectively absorbs information from others
- The last word’s vector becomes a summary of the entire sentence
- That vector is matched against all words to predict the next one
- Then the process repeats

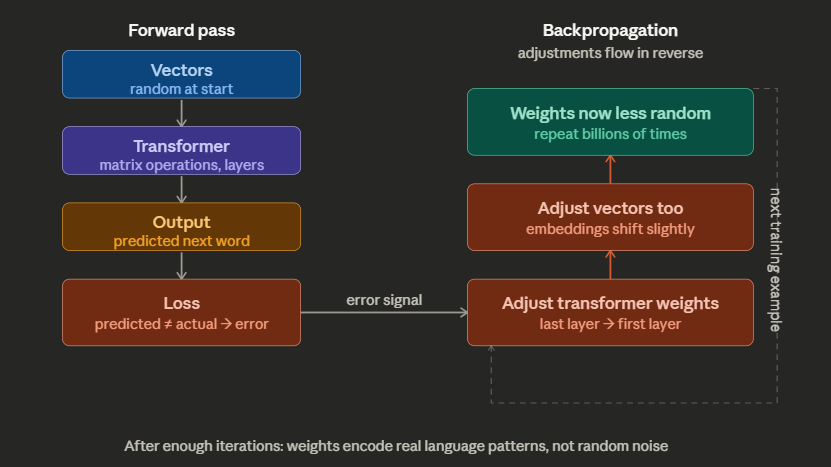
But how did we reach a point where if we put a sentence inside a transformer, it gives us a word that is most likely going to come next? How did we arrive at this position? Because post-training both the vectors and the weights inside a transformer are static, they do not update. How did it become so that just multiplying a few numbers gives us the next word and in turn on a repeating process a whole paragraph or a whole piece of code?
Well the start of it all is very random. You first define the number of parameters your vector is going to have and also make the matrices in the transformer be compatible with your vectors. Once that is set up, everything is random: the weights inside your transformer are random, the numbers inside your vectors for all the parameters are random. If you do the operation, if you put in some input, the next word it finds is wrong.
This is where the data you use to train your model comes in. It is mostly a frequentist approach where, across the data, we find that okay, after “I”, “am” is used a lot. So it should have a high probability but since everything in your vectors and transformer weights is random, it might be not very high. So we use back propagation. Here back propagation makes slight changes in all the variables involved till we collapse into a value that is the same as one we desire.
Back propagation has a sequence. In an LLM operation we have vectors, then the transformer, and then the context vector/output
So via back propagation we make slight changes in the transformer first across its thousands of layers from the last layer to the first layer and then changes in the vectors also. We make simultaneous changes so that we don’t mess things up too much.
And when we do this type of test of expected probability vs output thousands of millions of times, our weights and vectors go from random to something that is a bit more fine-tuned.
We start with a random chaos. We compare expectations with reality, massage the parameters and weights till we are close to our expectations, and then do the thousands of times and you have made a leading LLM model.
Notes: To call it just frequentist will be a huge simplification, it is more complicated than that. For example your data might not have the sentence “I am a cat. I love milk.” But it might have a lot of descriptions about what a cat is, what milk is, what animal is, and they love food. Basically, if the data is big enough, there will be enough context about everything, and that context will create implicit connection. Even if those connections are not explicitly mentioned, there is no need for anything verbatim or explicit, it can work on indirect basis also.
LLMs essentially have two types of memory:
- Parametric memory refers to all the data it was trained on and was ingrained into the transformer. They live on in the LLM in the forms of the weights the transformer has.
- The in-context window is basically the vectors that are passing through the LLM and a model can only process so much so that defines the context window.
This is also why you can think of whatever input you give to an LLM as if it were something you are giving to a person’s working memory. A person has only so much working memory before they get overwhelmed. And that is the biggest bottleneck in LLMs right now: the context window or the processing power of the transformer is not big enough that we can solve the most challenging problems. Well at first you might think of solutions like, “Hey what if instead of static weights we have some free weights?” there is something called LoRa that is working on it but the latency is a problem. Currently we rely on back propagation to change weights and vectors, which requires you to have a real-time loss function, which we don’t have in this case. So basically we are stuck with a small working memory for these damn robots.
Basically matrices is the bad kid and when a vector hangs out with the bad kid, it also becomes bad. Basically a matrix is a distorted grid and when you multiply it with a vector, it distorts the vector too in the same way it is distorted basically.
In a sense vector is a single entity; it is an arrow pointing towards some direction but matrix is information about two standard units and where they ended up after the distortion. And that distortion is the guide which tells us where any other vector would end up given that distortion is applied to it also. Basically if the standard units are 1, 0 and 0, 1, if they become 3, 0 and 0, 3, what would happen to any other vector? That we come to know by assembling that matrix using the standard units And multiplying our vector of interest
For AI, the vectors exist, and the transformer basically is a set of thousands of matrices, the vectors travel through these matrices and, at the end, become influenced by the parametric memory of the model itself and also the context they carry with each other as a group of words or sentences together.
Basically, words mean something as per the vectors. Right after the model is trained, they are no longer random; they are trained and mean something. As they go through the model weights and their presence with each other, they keep absorbing the parametric information and also the contextual information they carry themselves. By the end of it, the last token has the context enough to represent the whole sentence, kind of, and then when it is compared with the vector of all the words available, we find the most suitable word.